
Any Cables #35: summer heat 🥵
May-June 2026


This summer season is hot and full of amazing events, from the World Cup to RubyConf to GopherCon—what’s your pick? Hint: you can find us at any of these!
Highlights
Action Cable Next coming to Rails 8.2
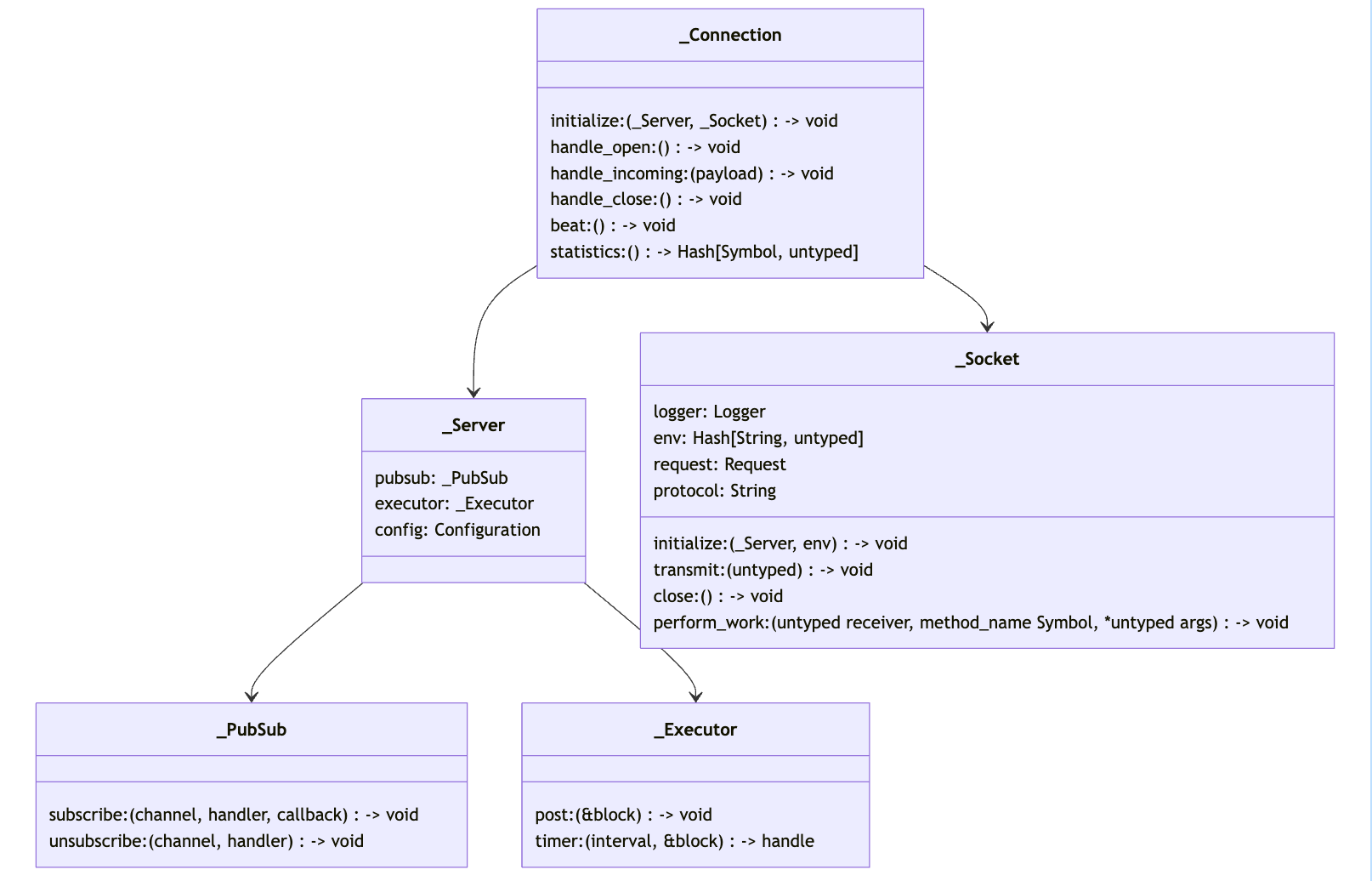
The long-awaited (~29 months to get merged) PR to Rails has been merged. It brings new foundation for the future Action Cable, ready to be async-ified or customized to your needs. There is more work to be done—we’ll see the final shape by Rails World in September! By the way, Team AnyCable is coming to Austin, come say “Hi!”.
News
Vercel announced WebSockets support (public beta) for Functions
This feature brings WebSockets protocol support to Functions, that is, it’s only about the transport. No pub/sub primitives, durable state, etc. Still, could be a good fit for short-term connections and RPC-over-WebSockets communication.
Posts
Choose your fighter: benchmarking 5 WebSocket servers for Node.js
: Socket.io 85%, uWS 87%, AnyCable 100%. Reconnect avalanche: Socket.io + CSR fails past 10K, uWS 9 s at 20K, AnyCable 0 s no restart. Footprint per idle connection: Socket.io ~52 KB, AnyCable Pro 18 KB, uWS 5 KB.")
This article is less about Node.js and WebSocket and more about how to do a healthy load test. Still, the numbers are worth checking out. The full comparison report is available here: https://anycable.io/compare/nodejs-websocket. More reports are coming!
Durable Streams at kernel speed
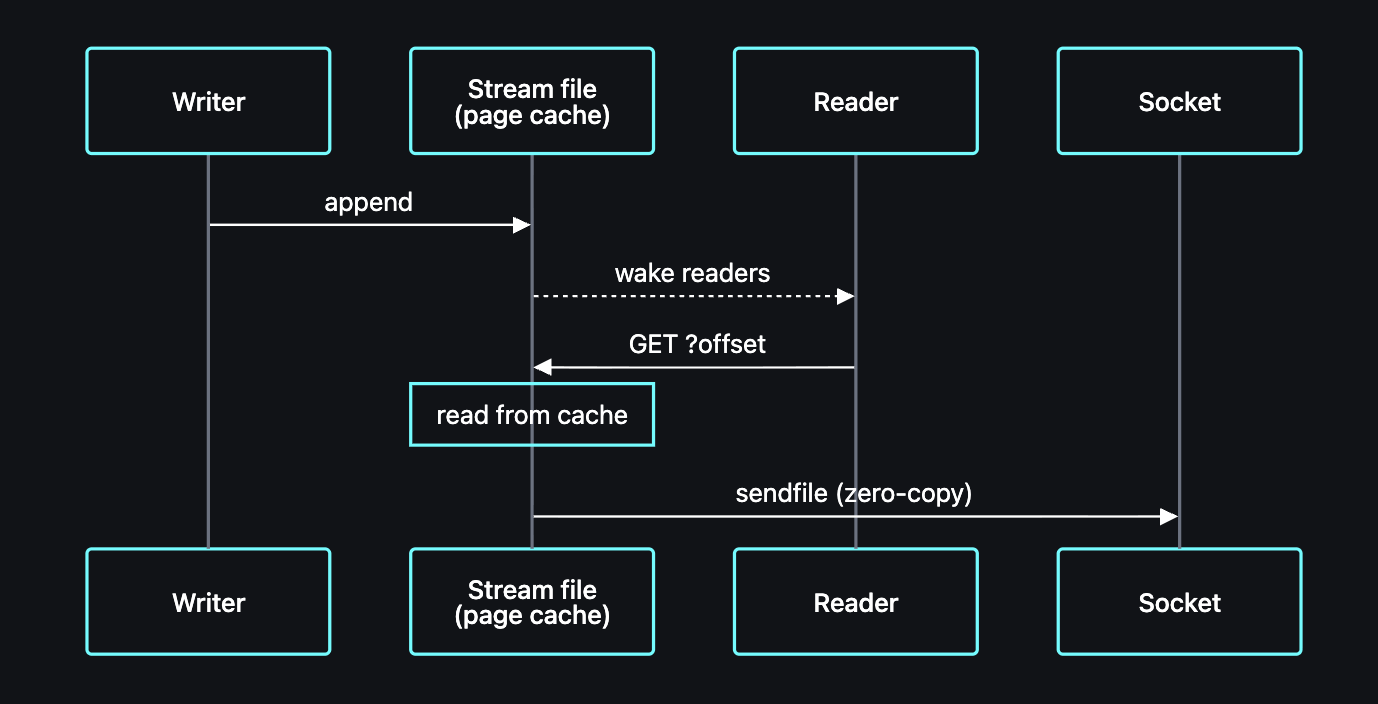
Electric engineers are experimenting with building a Durable Streams server in Rust, and the current results are impressive: 10x more writes/s than the reference Node.js implementation. The secret sauce is using zero-copy data passing via low-level syscalls—works perfectly for transmitting append-only logs.
Releases
The fork of Campfire built on top of AnyCable with multi-tenancy, threads, Slack import and more.
Centrifugo 6.8 brings PostgreSQL as a new broker backend (for streams history, presence, etc.). That’s exactly what is being proposed (and generated) for AnyCable. Stay tuned!
This release fixes some moderate CVEs and brings other improvements.
Frame of curiosity: GraphQL subscriptions, hot or not?
Remember how about 7-8 years ago, GraphQL was everywhere? Conferences, blog posts, podcasts, tons of open source libraries, and dozens of commercial products dedicated to a new (supposedly) silver bullet technology. Over the years, the excitement wore off, the reality kicked in, and torrents of “wtf?”-s washed the hype away. But not completely.
In 2026, we still have a lot of legacy apps that haven’t yet migrated off GraphQL and even some brave developers considering GraphQL for their new projects. A good portion of AnyCable customers have been using GraphQL Subscriptions in production for many years… and we know how painful it is.
Disclaimer: our GraphQL experience is mostly scoped to Rails applications using GraphQL Ruby under the hood, so it could differ from experience of using GraphQL subscriptions in other runtimes.
What is a GraphQL Subscription? It’s a mechanism for receiving live graph updates. Unlike regular GraphQL queries, subscription queries imply that the server will continuously push the graph fragments to the client to update its local state (or a store). For example:
subscription ItemSubscription {
itemAdded {
item {
id
title
description
}
user {
id
email
}
}
}When the client performs the query above, the server must register the interest of this client in the itemAdded subscription and deliver the requested data every time the subscription is triggered (while the client is connected). Unlike “publishing” in typical pub/sub systems, “triggering” doesn’t require providing the payload at the publication time, just the arguments for the subscription:
# somewhere in your code, say, in a mutation
item = Item.create!(item_params)
ApplicationSchema.subscriptions.trigger("itemAdded", {}, item)At the trigger time, the runtime must collect all the subscribed clients, execute their corresponding subscription queries with the provided arguments (item) and finally transmit the generated payloads down to each client (usually) over WebSockets.
Thus, every publication results in N query executions where N is the number of currently subscribed clients. And given that clients can ask for arbitrary graph nodes and fields, evaluating all these queries could be costly. And, in practice, it is.
Another problem with this very flexibly pub/sub-like mechanism and deferred payload generation is that the graph contents may be different for different users due to personalization aspects: localization, authorization, etc. Even if we restrict the usage of subscription queries only to the list of predefined graph fragments (for example, using persisted queries), we wouldn’t be able to generate the payload once and deliver it to everyone, i.e., GraphQL Subscriptions could not be emulated as regular pub/sub streams, in general. Moreover, to personalize payloads, we must store each subscribed client’s context somewhere.
GraphQL Ruby, for example, provides a workaround to optimize context-free subscriptions called broadcastable subscriptions. Basically, you explicitly mark graph nodes as broadcastable (=context-free), and if multiple clients subscribe to the same subgraph with only broadcastable nodes, live update payloads are generated once per event, not for each client individually. Still, we need to keep the state, we need to analyze and compare queries—perform a lot of work not needed when you use a good old stream/channel-based pub/sub interface.
Finally, by default, GraphQL Subscriptions do not provide order or delivery guarantees (i.e., they’re “at-most once”). You should either take care of connection losses at the application level (e.g., rehydrate the sate on reconnection) or use specific links or real-time servers. For example, you can achieve better delivery guarantees in your GraphQL on Rails application by using AnyCable JS SDK with Action Cable Link for Apollo and connecting to AnyCable server. Is it worth it?
Performance and reliable GraphQL Subscriptions are possible, but the cost is high. More tooling, more infra, more headache of figuring out what the hell is going on with the client state. I’d prefer to keep it simple. Here are the options:
Use generic but reliable pub/sub mechanism to deliver live data (AnyCable, Durable Streams, etc.)
Only broadcast context-free payloads generated at publication time to massive audiences (i.e., when the number of active subscribers is high); put the data to the GraphQL store at the client side manually (with AI agents, it’s no longer a rocket science)
Transmit signals over pub/sub to re-fetch queries when the number of subscribers is low (polling-like strategy)
Just don’t use GraphQL 😁